User guide
How to contribute to the data labelling process
This interface is the first step in the data labelling pipeline. From a list of digital copies of ancient manuscripts, a user can select a page and manually label its data from the labelling interface. In doing so, our users can help us to enhance the quality of our machine learning algorithms.
How data labelling works
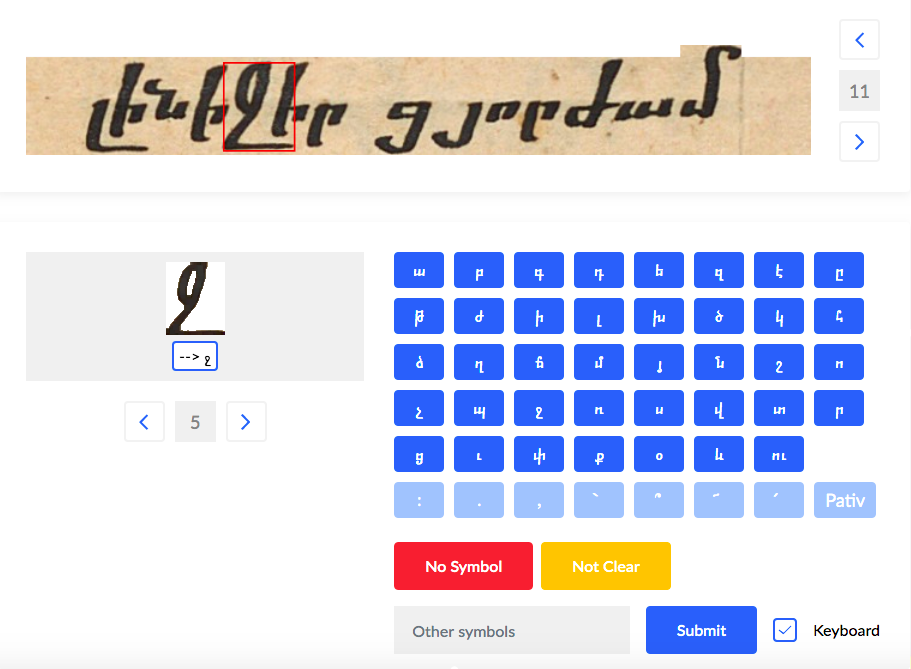
For our image-to-text software, we rely on part on a disciple called supervised learning. This is a subdomain of machine learning, that in a nutshell algorithms following its paradigm need a lot of examples of correctly labelled data to "learn" to predict the label (in our case the text) of new unseen examples. To have a way to collect such data, in larger amounts, we built a special pipeline for data labelling. It works as follows: one of our algorithms splits a given digital copy of a manuscript into rows, and then tries to locate characters or special groups of characters on each row. A user, then, sees a result of this localization on their screens and needs to select the correct answer for each instance of such images. In this way, we can quickly go over a large number of manuscripts and collect the necessary data.
How to play with and test machine learning algorithms
The main purpose of the Playground page is to give our users a feel of machine learning algorithms. On our server, we deployed a toy example of one of our main algorithms and on the browser, we created means to interact with an image using various image processing filters and certain geometric transformations. An image of a character or a group of characters is being displayed on the screen, and the user can apply the image transformations and ask what our algorithm sees, namely what character or group of characters the algorithm can read. In this way, one can get a very rough idea of how the image-to-text software may look. To reach the playground page simply follow the Check via model button on character images from particle repository or right click on the labels from Statistics page and follow the instructions there.

What is the particle repository
Particle repository is based on manually labelled images. Given a particular label (a single character or a group of characters), the repository collects various instances of that label. The users can explore the statistical properties of their shapes as well as see the variates of the same symbols in ancient writings.
